该模型基于 Würstchen 架构构建,与 Stable Diffusion 等其他模型的主要区别在于它在更小的 latent 空间中工作。为什么这很重要?latent 空间越小,推理速度就越快,训练成本也就越低。latent 空间有多小?Stable Diffusion 使用压缩系数 8,从而将 1024x1024 图像编码为 128x128。Stable Cascade 的压缩系数为 42,这意味着可以将 1024x1024 图像编码为 24x24,同时保持清晰的重建。然后在高度压缩的 latent 空间中训练文本条件模型。与 Stable Diffusion 1.5 相比,该架构的先前版本实现了 16 倍的成本降低。
因此,这种模型非常适合注重效率的用途。此外,所有已知的扩展(如微调、LoRA、ControlNet、IP 适配器、LCM 等)也可以通过此方法实现。其中一些(微调、ControlNet、LoRA)已经在训练和推理部分提供。
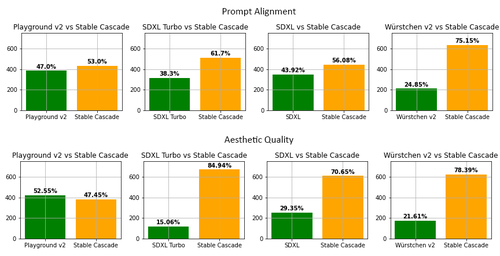
此外,Stable Cascade 在视觉和评估方面都取得了令人印象深刻的结果。根据我们的评估,在几乎所有比较中,Stable Cascade 在快速对齐和美观质量方面都表现最好。下图显示了使用部分提示(链接)和审美提示相结合的人类评估结果。具体来说,将 Stable Cascade(30 个推理步骤)与 Playground v2(50 个推理步骤)、SDXL(50 个推理步骤)、SDXL Turbo(1 个推理步骤)和 Würstchen v2(30 个推理步骤)进行了比较。
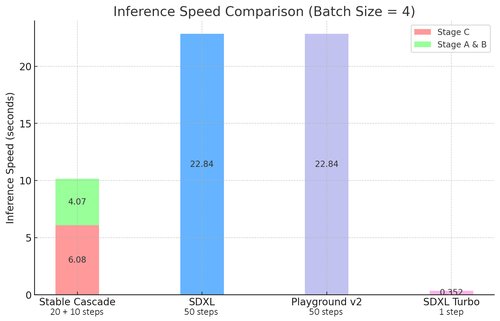
Stable Cascade 对效率的关注通过其架构和更高压缩的 latent 空间得到了证明。尽管最大的模型比 Stable Diffusion XL 多包含 14 亿个参数,但它仍然具有更快的推理时间,如下图所示。

模型概览
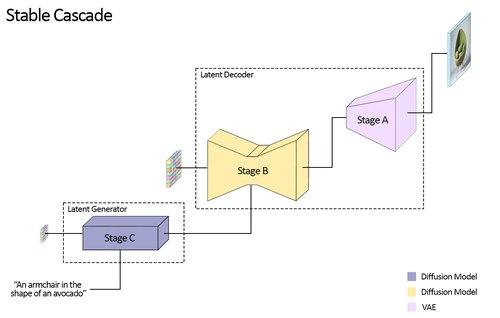
Stable Cascade 由三个模型组成:Stage A、Stage B和Stage C,代表生成图像的级联,因此得名“Stable Cascade”。A 阶段和 B 阶段用于压缩图像,类似于 Stable Diffusion 中 VAE 的工作。然而,如前所述,通过此设置可以实现更高的图像压缩。此外,阶段 C 负责在给定文本提示的情况下生成小的 24 x 24 latent。下图直观地展示了这一点。请注意,阶段 A 是 VAE,阶段 B 和 C 都是扩散模型。
对于此版本,我们为阶段 C 提供两个检查点,两个为阶段 B,一个为阶段 A。阶段 C 提供 10 亿和 36 亿参数版本,但我们强烈建议使用 36 亿版本,因为大多数工作都是投入其微调。Stage B 的两个版本分别达到 7 亿和 15 亿个参数。两者都取得了很好的结果,但 15 亿更擅长重建微小而精细的细节。因此,如果您使用每个版本的较大变体,您将获得最佳结果。最后,阶段 A 包含 2000 万个参数,并且由于其尺寸较小而被固定。
入门
本节将简要概述如何开始使用 Stable Cascade。
推理
可以通过推理部分提供的笔记本来运行模型。您将找到有关下载模型、计算要求的更多详细信息以及有关如何使用模型的一些教程。具体来说,为以下用例提供了四个 notebook:
文本转图像
一个紧凑的 notebook 为您提供文本到图像、图像变化和图像到图像的基本功能。
- 文本转图像
Cinematic photo of an anthropomorphic penguin sitting in a cafe reading a book and having a coffee.

- 图像变化
该模型还可以理解图像 embedding,这使得生成给定图像的变体成为可能(左)。这里没有提示。

- 图像到图像
这就像往常一样,通过将图像噪声增加到特定点,然后让模型从该起点生成。此处,左侧图像的噪声已达到 80%,标题为:
A person riding a rodent.

此外,该模型也可以在 diffusers 🤗库中访问。您可以在此处找到文档和用法。
ControlNet
这个 notebook 展示了如何使用我们训练过的 ControlNet 或如何使用您自己为 Stable Cascade 训练的 ControlNet。在此版本中,我们提供以下 ControlNet:
- 修复/修复

- 人脸识别

注意:Face Identity ControlNet 将在稍后发布。
- 边缘检测

- 超分辨率

这些都可以通过同一个 notebook 使用,并且只需要更改每个 ControlNet 的配置。推理指南中提供了更多信息。
LoRA
我们还提供了我们自己的训练实现以及使用具有 Stable Cascade 的 LoRA,可用于微调文本条件模型(阶段 C)。具体来说,您可以添加和学习新的令牌,并将 LoRA 层添加到模型中。这个 notebook 展示了如何使用经过训练的 LoRA。例如,使用以下类型的训练图像在我的狗上训练 LoRA:

根据提示,让我生成以下我的狗的图像:
Cinematic photo of a dog [fernando] wearing a space suit.

影像重建
最后,对人们来说可能非常有趣的一件事,特别是如果您想从头开始训练自己的文本条件模型,甚至可能使用与我们的阶段 C 完全不同的架构,那就是使用 Stable Cascade 的(Diffusion)自动编码器,它可以在高度压缩的空间中工作。就像人们使用 Stable Diffusion 的 VAE 来训练自己的模型(例如 Dalle3)一样,您可以以相同的方式使用 Stage A 和 B,同时受益于更高的压缩,从而使您能够更快地训练和运行模型。这个 notebook 展示了如何对图像进行编码和解码,以及您可以获得哪些具体好处。例如,假设您有以下一批尺寸为4 x 3 x 1024 x 1024的图像:

您可以将这些图像编码为压缩尺寸4 x 16 x 24 x 24,从而获得空间压缩系数 1024 / 24 = 42.67。之后,您可以使用阶段 A 和 B 将图像解码回4 x 3 x 1024 x 1024,得到以下输出:

正如您所看到的,即使对于小细节,重建也非常接近。使用标准 VAE 等不可能进行此类重建。这个 notebook 为您提供了更多信息和简单代码来尝试。
训练
我们提供从头开始训练 Stable Cascade、微调、ControlNet 和 LoRA 的代码。您可以在 training 文件夹中找到有关如何执行此操作的全面说明。
提醒
代码库正处于早期开发阶段。您可能会遇到意外错误或未完美优化的训练和推理代码。我们提前对此表示歉意。如果有兴趣,我们将继续发布更新,旨在引入最新的改进和优化。此外,我们非常乐意收到愿意做出贡献的人的想法、反馈甚至更新。干杯。
Gradio 应用
首先通过运行以下命令安装 gradio 和 diffusers:
pip3 install gradio pip3 install accelerate # optionally pip3 install git+https://github.com/kashif/diffusers.git@wuerstchen-v3
然后在项目的根目录运行以下命令:
PYTHONPATH=./ python3 gradio_app/app.py