让我们使用名为GPT爬虫的新开源项目在短短两分钟内创建一个自定义 GPT。提供一个站点 URL,它将抓取该站点 URL 并将其用作 GPT 的知识库。
您可以共享此 GPT 或将其作为自定义助手集成到您的网站和应用程序中。
为什么从网站创建自定义 GPT
作者基于Builder.io 文档、论坛和github 上的示例项目创建了第一个自定义 GPT ,它现在可以通过代码片段回答有关将Builder.io集成到您的网站或应用程序中的详细问题。您可以在这里尝试(目前需要付费 ChatGPT 计划)。
作者希望通过使我们的文档网站具有交互性,人们可以使用聊天界面更简单地找到他们正在寻找的答案。
这不仅有助于提高可发现性,节省人们的时间,而不必深入查找他们需要的特定文档,而且还可以个性化结果,因此即使是最深奥的问题也可以得到解答。
此方法几乎可以应用于任何事物,以使用网络上任何资源的最新信息创建自定义机器人。
GPT 爬虫程序入门
首先,我们将使用刚刚开源的这个新的 GPT 爬虫项目。
克隆存储库
首先,我们需要做的就是克隆存储库,我们可以通过一个简短的git clone命令来完成。
git clone https://github.com/builderio/gpt-crawler
安装依赖项
克隆后,cd 进入存储库,然后使用 npm install 安装依赖项。
cd gpt-crawler npm install
配置爬虫
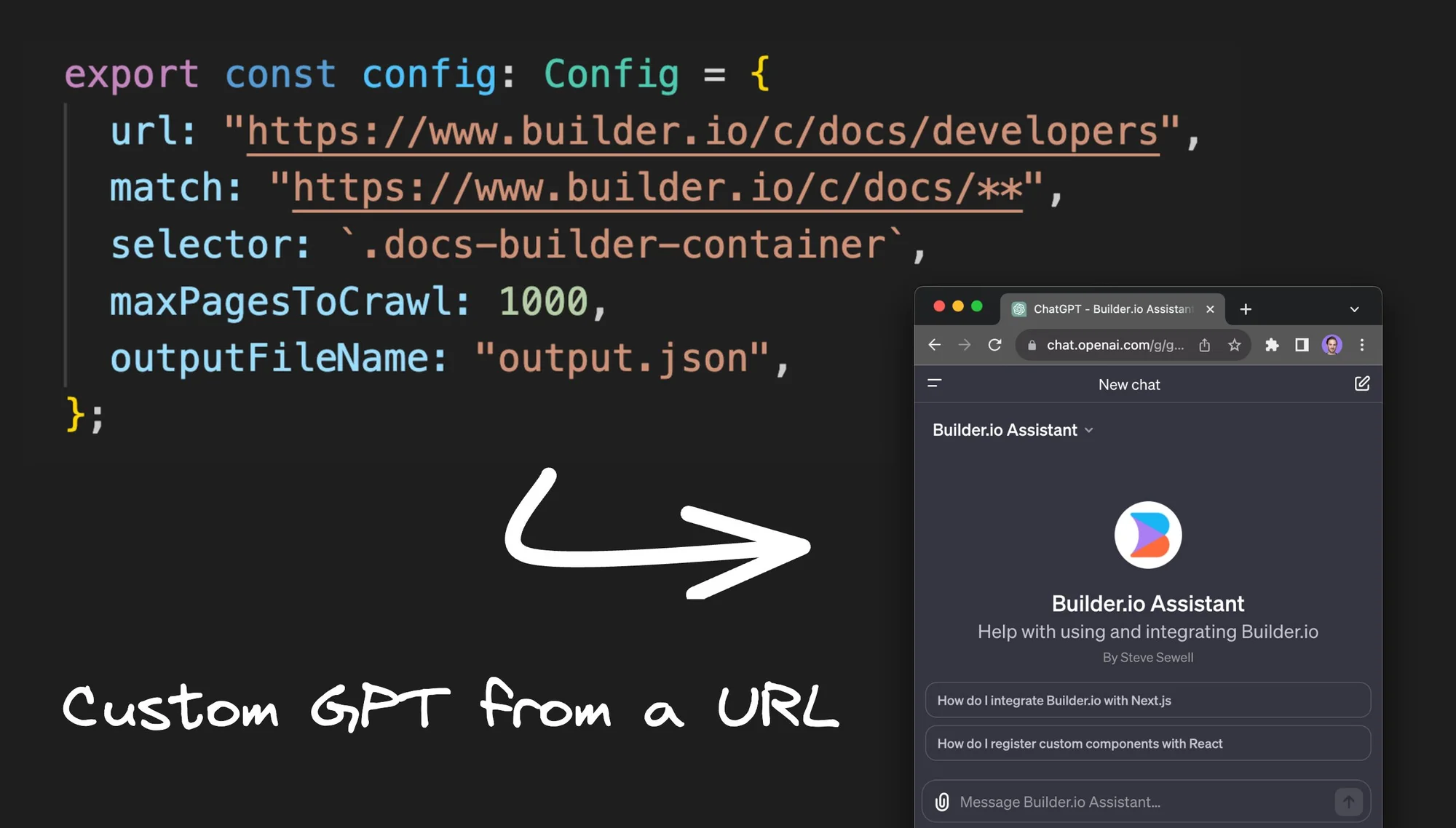
接下来,打开文件config.ts并提供我们的配置。在此文件中,我们指定一个基本 URL 作为爬取的起点,并定义在后续页面上爬取的链接。我们还可以设置一个匹配模式;例如,我可能只想抓取“docs”并排除其他所有内容。
export const config: Config = {
// Start the crawl at this URL
url: "https://www.builder.io/c/docs/developers",
// Only crawl URLs matching this pattern
match: "https://www.builder.io/c/docs/**",
// Only grab the text from within this selector
selector: `.docs-builder-container`,
// Don't crawl more than 1000 pages
maxPagesToCrawl: 1000,
// The file name that our results will output to
outputFileName: "output.json",
};建议还提供一个选择器。例如,对于 Builder 文档,将其设置为仅抓取特定区域,而不抓取侧边栏、导航或其他元素。
运行爬虫
现在,我们可以在终端中运行npm start,爬虫会实时处理我们的页面。
npm start
该爬虫使用无头浏览器,因此它可以包含任何标记,甚至是那些纯粹客户端呈现的标记。您还可以自定义爬虫来登录站点以爬取非公开信息。
上传您的知识文件
爬取完成后,我们将得到一个新的output.json文件,其中包括标题、URL 以及从所有已爬取页面中提取的文本。
[
{
"title": "Creating a Private Model - Builder.io",
"url": "https://www.builder.io/c/docs/private-models",
"html": "..."
},
{
"title": "Integrating Sections - Builder.io",
"url": "https://www.builder.io/c/docs/integrate-section-building",
"html": "..."
},
...
]创建自定义 GPT(UI 访问)
现在,我们可以通过创建新的 GPT、配置它,然后上传我们刚刚生成的知识文件,将其直接上传到 ChatGPT。上传后,这个 GPT 助手将获得这些文档中的所有信息,并能够回答有关它们的无限的问题。
创建自定义助手(API访问)
或者,如果您想将其集成到您自己的产品中,您可以到OpenAI API 仪表板,创建一个新的助手,并以类似的方式上传生成的文件。
这样,您就可以通过 API 访问助手,在您的产品中提供定制的帮助,这些帮助直接从您的文档或任何其他网站获取有关您产品的具体知识,只需提供 URL 并抓取网络即可。