Magika 是谷歌人工智能驱动的文件类型识别系统,以帮助准确检测二进制和文本文件类型。在底层,Magika 采用定制的、高度优化的深度学习模型,即使在 CPU 上运行,也能在几毫秒内实现精确的文件识别。
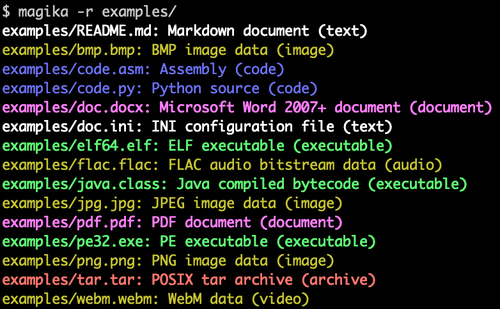
Magika 命令行工具,用于识别不同文件集的类型
您可以立即尝试 Magika Web 演示,或者使用命令行执行pip install magika将其安装为 Python 库和独立命令行工具(输出如上所示) 。
为什么识别文件类型很困难
自计算早期以来,准确检测文件类型对于确定如何处理文件至关重要。Linux 配备了libmagic和文件实用程序,50 多年来它们一直是文件类型识别的事实上的标准。如今,网络浏览器、代码编辑器和无数其他软件都依赖文件类型检测来决定如何正确呈现文件。例如,现代代码编辑器使用文件类型检测来选择当开发人员开始输入新文件时要使用的语法着色方案。
准确的文件类型检测是一个众所周知的难题,因为每种文件格式都有不同的结构,或者根本没有结构。这对于文本格式和编程语言来说尤其具有挑战性,因为它们具有非常相似的结构。到目前为止,libmagic和大多数其他文件类型识别软件一直依赖手工设计的启发式集合和自定义规则来检测每种文件格式。
这种手动方法既耗时又容易出错,因为人类很难手动创建通用规则。特别是对于安全应用程序来说,创建可靠的检测尤其具有挑战性,因为攻击者不断试图将检测与敌方制作的有效负载混淆。
为了解决这个问题并提供快速准确的文件类型检测,我们研究和开发了 Magika,一种新的 AI 支持的文件类型检测器。在底层,Magika 使用定制的、高度优化的深度学习模型,该模型是使用Keras设计和训练的,大小仅为约 1MB。在推理时,Magika 使用 Onnx作为推理引擎,以确保在几毫秒内识别文件,几乎与非 AI 工具(甚至在 CPU 上)一样快。
Magika 的性能
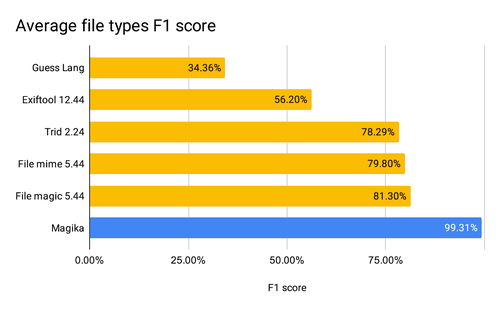
在我们的 1M 文件基准测试中,Magika 检测质量与其他工具相比
性能方面,Magika 凭借其 AI 模型和大型训练数据集,在包含 100 多种文件类型的 1M 文件基准测试上进行评估时,其性能比其他现有工具高出约 20%。按文件类型细分,如下表所示,我们发现文本文件的性能提升更大,包括其他工具可能难以处理的代码文件和配置文件。
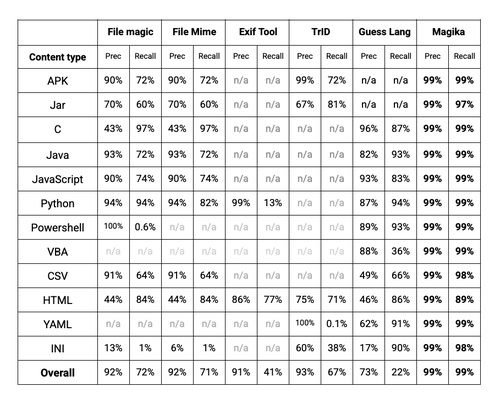
各种文件类型识别工具针对我们的基准测试中包含的所选文件类型的性能 - n/a 表示该工具未检测到给定的文件类型。
Magika 在谷歌的应用
在内部,Magika 被大规模使用,通过将 Gmail、云端硬盘和安全浏览文件路由到适当的安全和内容策略扫描程序来帮助提高 Google 用户的安全性。通过查看每周平均数千亿个文件可以发现,与我们之前依赖手工规则的系统相比,Magika 将文件类型识别准确性提高了 50%。特别是,准确率的提高使我们使用的专门的恶意 AI 文档扫描仪扫描出的文件数量增加了 11% ,并将未识别文件的数量减少到 3%。
Magika 与 VirusTotal 即将集成,将补充该平台现有的 Code Insight 功能,该功能利用 Google 的生成式 AI 来分析和检测恶意代码。Magika 将在 Code Insight 分析文件之前充当预过滤器,提高平台的效率和准确性。由于 VirusTotal 的协作性质,这种集成直接为全球网络安全生态系统做出了贡献,营造了更安全的数字环境。
开源 Magika
通过开源 Magika,我们的目标是帮助其他软件提高文件识别的准确性,并为研究人员提供大规模识别文件类型的可靠方法。
Magika 代码和模型可以在 Apache2 许可证下在 Github 上免费获取。Magika 还可以通过 pypi 包管理器快速安装为独立实用程序和 Python 库,只需输入pip install magicika即可,无需 GPU。如果您想使用 TFJS 版本,我们还有一个实验性npm 包。
使用介绍
安装
Magika 在 PyPI 上可用:
$ pip install magika
在 Docker 中运行
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
用法
Python 命令行
例子:
$ magika -r tests_data/ tests_data/README.md: Markdown document (text) tests_data/basic/code.asm: Assembly (code) tests_data/basic/code.c: C source (code) tests_data/basic/code.css: CSS source (code) tests_data/basic/code.js: JavaScript source (code) tests_data/basic/code.py: Python source (code) tests_data/basic/code.rs: Rust source (code) ... tests_data/mitra/7-zip.7z: 7-zip archive data (archive) tests_data/mitra/bmp.bmp: BMP image data (image) tests_data/mitra/bzip2.bz2: bzip2 compressed data (archive) tests_data/mitra/cab.cab: Microsoft Cabinet archive data (archive) tests_data/mitra/elf.elf: ELF executable (executable) tests_data/mitra/flac.flac: FLAC audio bitstream data (audio) ...
$ magika code.py --json
[
{
"path": "code.py",
"dl": {
"ct_label": "python",
"score": 0.9940916895866394,
"group": "code",
"mime_type": "text/x-python",
"magic": "Python script",
"description": "Python source"
},
"output": {
"ct_label": "python",
"score": 0.9940916895866394,
"group": "code",
"mime_type": "text/x-python",
"magic": "Python script",
"description": "Python source"
}
}
]$ cat doc.ini | magika - -: INI configuration file (text)
$ magika -h
Usage: magika [OPTIONS] [FILE]...
Magika - Determine type of FILEs with deep-learning.
Options:
-r, --recursive When passing this option, magika scans every
file within directories, instead of
outputting "directory"
--json Output in JSON format.
--jsonl Output in JSONL format.
-i, --mime-type Output the MIME type instead of a verbose
content type description.
-l, --label Output a simple label instead of a verbose
content type description. Use --list-output-
content-types for the list of supported
output.
-c, --compatibility-mode Compatibility mode: output is as close as
possible to `file` and colors are disabled.
-s, --output-score Output the prediction score in addition to
the content type.
-m, --prediction-mode [best-guess|medium-confidence|high-confidence]
--batch-size INTEGER How many files to process in one batch.
--no-dereference This option causes symlinks not to be
followed. By default, symlinks are
dereferenced.
--colors / --no-colors Enable/disable use of colors.
-v, --verbose Enable more verbose output.
-vv, --debug Enable debug logging.
--generate-report Generate report useful when reporting
feedback.
--version Print the version and exit.
--list-output-content-types Show a list of supported content types.
--model-dir DIRECTORY Use a custom model.
-h, --help Show this message and exit.
Magika version: "0.5.0"
Default model: "standard_v1"
Send any feedback to magika-dev@google.com or via GitHub issues.有关详细文档,请参阅python 文档。
Python API
例子:
>>> from magika import Magika >>> m = Magika() >>> res = m.identify_bytes(b"# Example\nThis is an example of markdown!") >>> print(res.output.ct_label) markdown
有关详细文档,请参阅python 文档。
实验性 TFJS 模型和 npm 包
我们还为有兴趣在网络应用程序中使用的人们提供 Magika 作为实验包。请注意,Magika JS 实现性能明显较慢,每个文件预计花费 100 毫秒以上。
详细内容请参见js文档。
开发设置
我们用poetry来开发和打包:
$ git clone https://github.com/google/magika $ cd magika/python $ poetry shell && poetry install $ magika -r ../tests_data
运行测试:
$ cd magika/python $ poetry shell $ pytest tests/
重要文档
要了解有关如何使用它的更多信息,请参阅Magika 文档站点。
来自: