在从零开始构建大语言模型一书中,您将了解到LLM如何工作。在这本富有洞察力的书中,畅销书作家塞巴斯蒂安·拉斯卡(Sebastian Raschka)将逐步指导您创建自己的LLM,并用清晰的文字、图表和示例解释每个阶段。您将从最初的设计和创建到对通用语料库进行预训练,一直到针对特定任务进行微调。
从零开始构建大语言模型教您如何:
- 规划和编码LLM的所有部分
- 准备适合LLM训练的数据集
- 使用您自己的数据微调LLM以进行文本分类
- 使用人工反馈来确保您的LLM遵循指示
- 将预训练权重加载到LLM中
为 ChatGPT、Bard 和 Copilot 等尖端人工智能工具提供支持的大语言模型 (LLM) 看起来像是一个奇迹,但它们并不是魔法。本书通过帮助您从头开始建立自己的LLM来揭开LLM的神秘面纱。您将获得关于LLM如何运作的独特且有价值的见解,学习如何评估其质量,并掌握具体的技术来调整和改进它们。
在本书中,您用于训练和开发自己的小型但实用的模型的过程遵循用于交付大规模基础模型(如 GPT-4)的相同步骤。您的小型LLM可以在普通笔记本电脑上开发,并且您将能够将其用作您自己的私人助理。
关于这本书
从零开始构建大语言模型是构建您自己的LLM的独一无二的指南。在其中,机器学习专家兼作家 Sebastian Raschka 揭示了LLM是如何在幕后工作的,揭开了生成式人工智能黑匣子的盖子。这本书充满了构建LLM的实用见解,包括构建数据加载管道、组装其内部构建模块以及微调技术。随着您的进展,您将逐渐将基本模型转变为文本分类器工具和遵循您的对话指令的聊天机器人。
MEAP 于2023年12月开始,预计于2025年初出版。
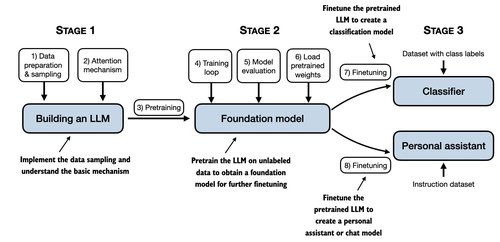
本书内容脉络
关于读者
适合了解 Python 的读者。开发机器学习模型的经验很有用,但不是必需的。
关于作者
Sebastian Raschka十多年来一直致力于机器学习和人工智能领域。Sebastian 于 2022 年加入 Lightning AI,目前专注于人工智能和LLM研究、开发开源软件以及创建教育材料。在此之前,Sebastian 曾在威斯康星大学麦迪逊分校担任统计系助理教授,专注于深度学习和机器学习研究。他对教育充满热情,并以其关于使用开源软件进行机器学习的畅销书而闻名。
目录
- 理解大语言模型
- 处理文本数据
- 理解注意力机制
- 从零开始实现GPT模型来生成文本
- 无标签数据的预训练
- 文本分类的微调
- 根据人类反馈进行微调
- 在实践中使用大语言模型
来自: